3.5 MCMC
1 MCMC
Hierarchical models can get very complex quickly, creating big computational headaches. For
A computational strategy is to set up a Markov chain with stationary distribution
Compared with Markov chain in probability, the notation here is more Bayesian.
A (stationary) Markov chain with transition kernel
The marginal distribution of
This is a directed graphical model:
If
A sufficient condition for stationary distribution is detailed balance:
Because this leads to
A Markov chain with detailed balance is called reversible, i.e. if
Note that
If an MC with stationary distribution
- Irreducible:
: . - Aperiodic:
.
Then
The proof is beyond scope of this note.
So the strategy is to find
2 Gibbs Sampler
Denote the parameter vector
- Initialize
. - For
: - For
, - Sample
(*)
- Sample
- Record
.
- For
means parameters apart from .
Variations on (*):
- Update one random coordinate
. - Update coordinates in random order.
Advantage for hierarchical priors:
- Only need to sample low-dimensional conditional distributions:
This is especially easy if using conjugate priors at all levels, often can be parallelized.
2.1 Stationarity of
If
Consider updating any one (fixed) coordinate
If
so
So updating any coordinate preserves posterior distribution, and updating coordinates in any order also does.
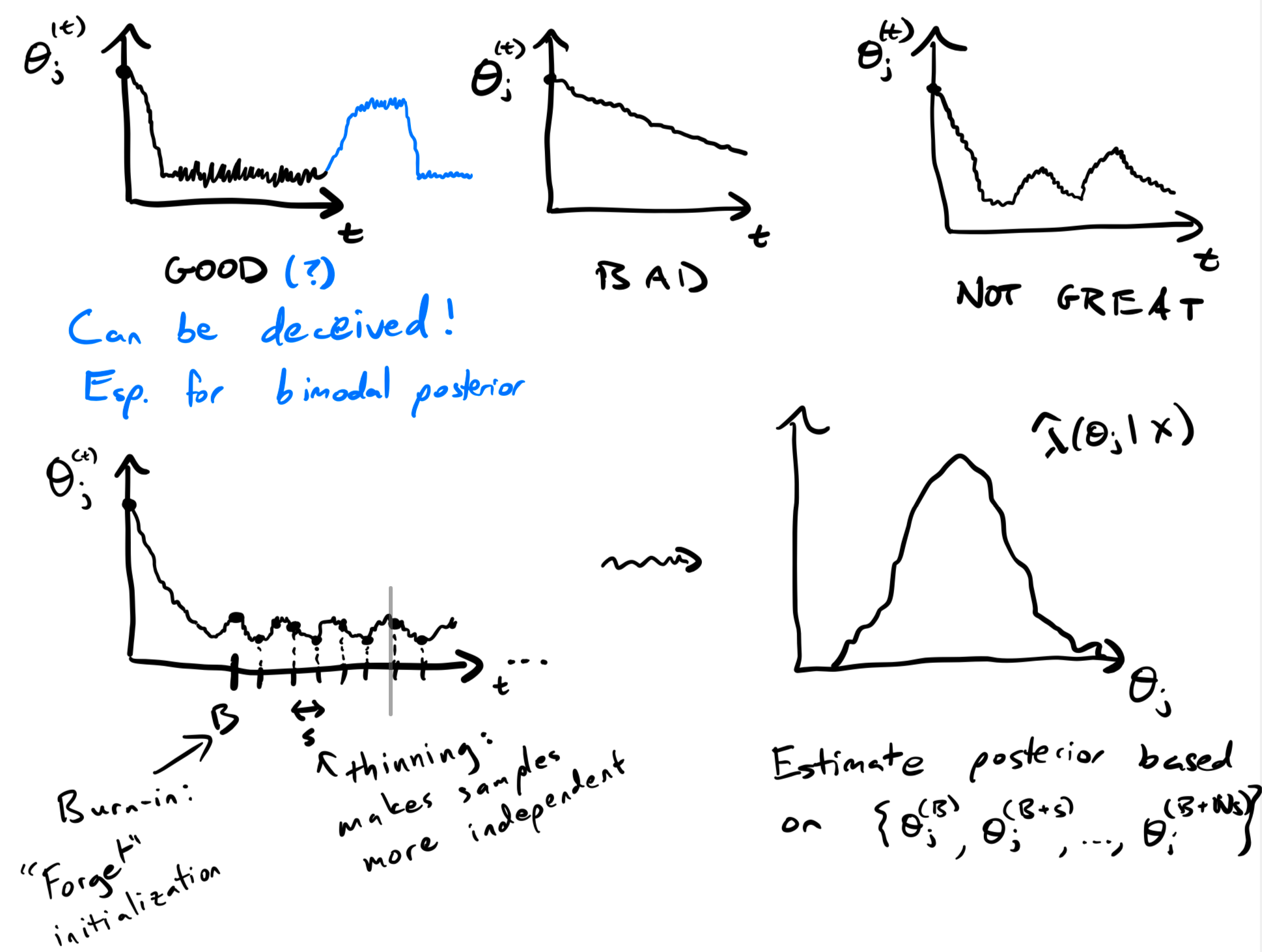
3 MCMC in Practice
- In theory, pick any initialization
and valid kernel , sample long enough s.t. .
Do it againmore times, we have samples from . - In practice, we need to determine if we've sampled long enough.
For the last (desirable) one, the posterior mean is
But this will cause Gibbs to take a long time to mix. (The image is a very sharp ellipse.) A better parameterization is
4 Empirical Bayes
Back to the Gaussian hierarchical model
For any "reasonable" prior,
If prior doesn't matter much, why use one? Could just estimate
from data however we want, "plug it in".
UMVUE:
Call Empirical Bayes a hybrid approach in which hyperparameters are treated as fixed, others treated as random.